In this post I will outline an implementation of a serverless service to run regression models (fitting and predicting) in AWS. Under the hood it is using Python’s statsmodels package and the formula interface. Sending JSON data and a model formula to the API will fit a linear model using ordinary least squares (OLS) and save the model to S3. The model can then available to predict new observations.
Architecture Overview
The service can be accessed via REST-API; the background service consists of two lambda functions, one for fitting models, the other for running predictions based on fitted models. Fitted models are stored as .pickle files in S3:
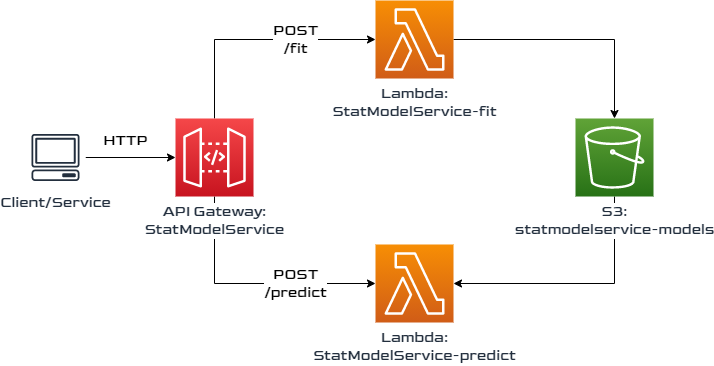
Creating Models and Getting Predictions
The API accepts POST requests on two paths, /fit and /predict, both integrated with lambda as lambda proxies, i.e. HTTP requests are passed through to lambda as-is.
/fit
The payload for the POST request on /fit consists of the model formula (in R notation) and the data (in JSON format). A simple example for the evaluation of an A/B test would look like
{
"formula": "Outcome ~ Treatment",
"data": [
{"Treatment": "A", "Outcome": 110},
{"Treatment": "A", "Outcome": 90},
{"Treatment": "A", "Outcome": 120},
{"Treatment": "A", "Outcome": 80},
{"Treatment": "A", "Outcome": 100},
{"Treatment": "B", "Outcome": 70},
{"Treatment": "B", "Outcome": 110},
{"Treatment": "B", "Outcome": 100},
{"Treatment": "B", "Outcome": 80},
{"Treatment": "B", "Outcome": 90}
]
}
The response is the modelId which you will need for retrieving the fitted model and some modelInfo containing statistical measures of the model and its parameters, including the parameter point estimates, their standard error, t-statistics and p-values:
{
"modelId": "c73a00ff-2a3e-444f-baa6-99834812bd3a",
"modelInfo": {
"Intercept": {
"estimate": 100.00000000000001,
"se": 7.0710678118654755,
"t": 14.142135623730953,
"p": 6.077960694342541e-07
},
"Treatment[T.B]": {
"estimate": -9.999999999999993,
"se": 10.000000000000004,
"t": -0.9999999999999989,
"p": 0.34659350708733455
}
}
}
/predict
To predict the outcome variable using a fitted model you POST your payload to the /predict path of the API. The payload consists of the model ID and the data (again in JSON format)
{
"modelId": "c73a00ff-2a3e-444f-baa6-99834812bd3a",
"data": {"Treatment": "A"}
}
Note, that data is a map/dict, not an array, since the code is expected to process one new observation at a time.
The response (body) just contains the predicted value
{
"prediction": 100.00000000000001
}
Code
The full code including configuration files is available on github. Follow the readme to deploy the service in your AWS account using AWS SAM.